
Introduction: Beyond the Hype, Into the Weeds
AI in pharma is not a magic wand – it is the right time to put it to work. Advances in language models, the increasing accessibility of enterprise-ready AI, and a clearer understanding of how to combine different technologies have aligned with growing corporate appetite for practical solutions.
The result: we now have the conditions to deliver impact at scale, not experiments in isolation.
To illustrate, consider a high-impact challenge: automating the “Protocol-to-EDC” build – the process of turning a dense trial protocol into a fully configured EDC database. Generic chatbots fail here, but a domain-specific hybrid approach can finally crack the code.
What Makes “Protocol-to-EDC” So Hard?
Every trial begins with a hefty protocol (50+ pages detailing what to measure, when, and how). Translating that document into an EDC means designing all the case report forms (CRFs), fields, visit schedules, and edit checks exactly as the protocol dictates – a mission-critical task. It is also painstaking: a complex study build can take data managers 8–12 weeks of intense work, manually combing through the protocol line by line. Misinterpret one phrase and you might miss a key endpoint or collect data incorrectly.

GenericGPT, hard at work building an EDC.
This process is so challenging because protocols are sprawling and intricate. Crucial details are buried in paragraphs, tables, and appendices, and the language is highly specialized (often ambiguous). For example, a single sentence might read “Dose X on Day 1 and Day 8 of each 21-day cycle, adjust for toxicity per Appendix B” – which implies dozens of fields and conditional rules to configure. The upside to automating this correctly is huge: potentially shaving weeks off the study startup timeline.
We asked experienced data managers what they would want from an AI assistant for this task. They told us it must never miss critical data, use standards and include all expected fields, and allow human oversight with full traceability to the protocol. Unfortunately, off-the-shelf large language models fall short on all these fronts. Without clinical training they misinterpret specialized terms, struggle to connect scattered protocol details, and provide answers with no explanation – essentially a black box. Clearly, a more tailored approach is needed.
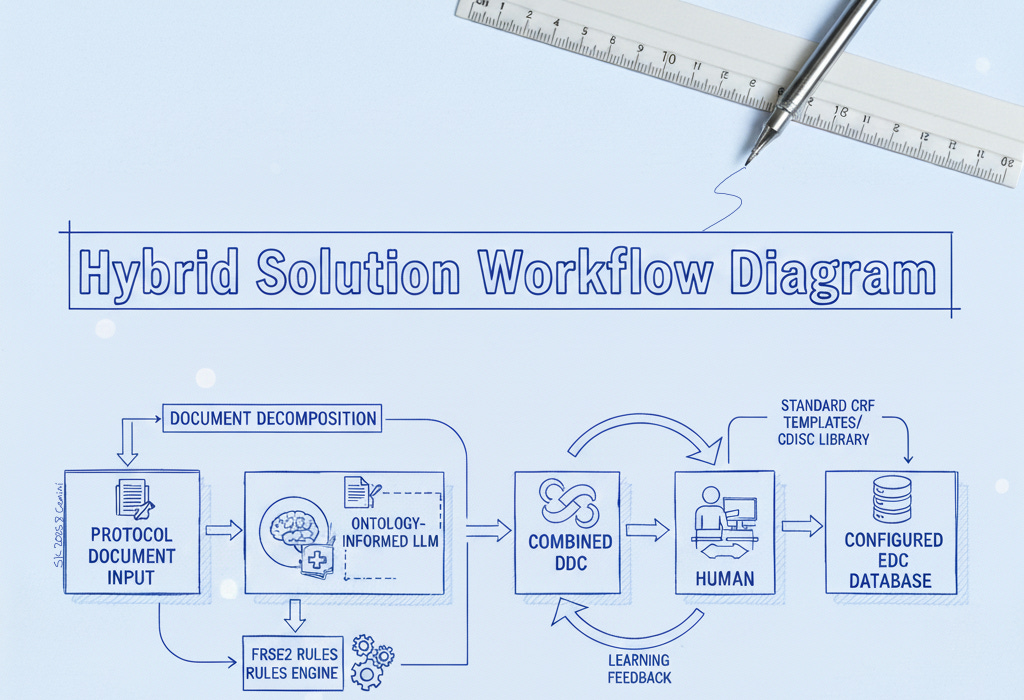
Our Hybrid Approach: AI + Rules + Human‑in‑the‑Loop
We found that solving the protocol-to-EDC challenge requires a blend of advanced AI technology, deterministic logic, and human expertise. Our hybrid solution combines a large language model (LLM) fortified with domain-specific knowledge, a set of rule-based parsers for structured data, and an interactive human review process in one unified workflow. Here’s how each component contributes:
Domain Knowledge Built-In: We prime the AI with extensive clinical trial knowledge – medical ontologies, standard CRF structures, and your organization’s own data dictionaries and standards. This domain pre-training means the AI “speaks the language” of your protocols, handling specialized terms and implicit requirements from day one.
Deterministic Rules as a Safety Net: We pair the AI with a rules engine to reliably catch structured or formulaic content with 100% accuracy. For example, a table of visits or a list of inclusion criteria is recognized and extracted exactly as written, and a phrase like “within 28 days of first dose” is interpreted precisely as a 28-day window. These rule-based extractions nail the clear-cut patterns and calculations, allowing the LLM to focus on the free-text nuances so that no obvious requirement is missed.
Structured Document Ingestion: We never feed the raw protocol directly into the AI. Instead, our proprietary parsing pipeline deconstructs the document into a structured format: sections are delineated, tables and lists are extracted, and context tags are applied. This organized input lets the AI retain context across the entire document – for instance, linking a procedure described on page 10 to the visit schedule on page 30 – resulting in a far more complete initial build.
Human-in-the-Loop Review: Finally, the system generates a draft EDC configuration that a data manager reviews through a dedicated interface. Every AI-suggested form, field, and edit check is traceable to its source text for easy verification. The reviewer can adjust anything on the spot (add a missed dropdown field, rename a label, tweak a rule’s logic, etc.), with changes updating instantly. Throughout this process, the human stays firmly in control, guiding and confirming the AI’s output to ensure accuracy and compliance.
The Blueprint. A blueprint?
Technology Deep Dive: How We Fix What LLMs Break
Generic AI alone isn’t sufficient for this task, so under the hood we engineered a specialized architecture to overcome the typical pitfalls of LLMs. The key technical elements of our solution (developed in partnership with Trigent) work together to ensure accuracy, consistency, and traceability:
Ontologies & Domain Knowledge Integration
We embed a rich clinical knowledge base into the AI, giving it a built-in understanding of trial terminology and context. This includes standard medical vocabularies and your organization’s own CRF templates and dictionaries. For example, the model knows that an “objective response” refers to RECIST tumor response criteria rather than guessing. By training the LLM with these domain semantics through fine-tuning and prompt engineering, we drastically reduce misinterpretations and naive errors that a generic model might make. In short, the LLM isn’t guessing – it’s drawing on a vetted clinical knowledge graph from the start.
Document Decomposition & Structured Input
Rather than dumping an unstructured protocol document into the AI, we feed it a well-organized representation of the content. Our proprietary pipeline parses and tags the protocol text into a hierarchy of labeled sections, tables, lists, and context markers. This ensures the LLM retains the document’s structure and knows how pieces relate to each other. For instance, if a procedure is described on page 10 and the schedule appears on page 30, our system explicitly links those references before the AI ever analyzes them. Preserving the protocol’s structure in this way prevents the “lost context” problem where details could be overlooked or confused. The result is a more complete and accurate draft configuration of the EDC, with all relevant details accounted for.
FRSE2 Rule Engine (Deterministic Patterns)
FRSE2 is our proprietary rules engine that acts as a safety net for all the formulaic, pattern-based content in the protocol. Many requirements follow predictable formats that FRSE2 can capture with perfect accuracy. For example, it will extract a list of inclusion criteria exactly as written, or interpret “within 28 days of first dose” as an explicit 28-day screening window. By letting rules handle these straightforward elements, no simple requirement slips through due to AI uncertainty, while the LLM concentrates on the nuanced free-text logic. In tandem, the rule engine and the AI cover each other’s blind spots. This division of labor is a key advantage of our approach – marrying the precision of deterministic algorithms with the flexibility of AI reasoning.
CRF Templates & CDISC Alignment
Our system also leverages standard eCRF templates and industry data standards (like CDISC) from the outset. As the AI interprets the protocol, it automatically maps recognized data points to pre-built form templates with controlled terminology. For instance, if the protocol calls for a lab test or a vital sign to be collected, the platform suggests using a standard form that includes fields for the result value, unit, normal range, etc., all aligned with CDISC/CDASH guidelines. This template-driven approach (co-developed with Trigent) fills in the implicit gaps that an experienced data manager would anticipate, even if the protocol doesn’t spell them out. By baking industry standards into the process, the initial EDC build comes out immediately consistent with regulatory expectations and common conventions – which means far less rework for your team and smoother downstream integration (for example, when mapping to SDTM datasets).
Human-in-the-Loop Interface
Even with all these automation layers, we keep the data manager in the driver’s seat. The platform provides an interactive review interface where every AI-generated form, field, and edit check is linked to the exact excerpt of the protocol that prompted it. This one-click traceability allows the reviewer to quickly validate each suggestion without hunting through the document. The data manager can modify anything the AI proposes with just a few clicks – change a field label, add a dropdown option, remove an extraneous form, or adjust an edit check’s logic – and the system instantly updates the configuration. This level of transparency not only streamlines quality control, it also builds trust in the AI’s output by making every decision explainable. The interface even flags any sections of the protocol that didn’t get mapped to the EDC, so the team can double-check that nothing important was overlooked. In the end, your team has the final say on the build – the AI works as a smart assistant, but humans make the decisions.
Experience-Based Learning Loop
Our solution continuously learns and improves with each study build. When the human reviewer makes a correction or adds something the AI initially missed, that feedback is fed back into our knowledge base and used to refine the model. The next time we encounter a similar protocol, the system will handle it more adeptly, having “learned” from the prior experience – much like a junior colleague growing more seasoned after mentorship from a veteran. This ongoing learning capability is a proprietary advantage of our platform; a generic out-of-the-box model won’t automatically get better in this way. The more you use the system, the smarter and more efficient it becomes, further accelerating your future EDC builds.

Approximately…
What Comes Next
The protocol-to-EDC bottleneck has long been treated as an unavoidable burden. It does not need to be. By combining language models with deterministic rules, structured ingestion, and human oversight, it is possible to shrink a process measured in months down to days, while improving traceability and reducing risk.
For CRO leaders and data operations teams, the next step is not about chasing hype or buying into generic tooling. It is about asking what kind of technology mix can fit into your workflows, align with standards, and earn the trust of the experts who have to use it.
We believe this hybrid approach is one practical example of that direction. Whether it is called “AI-assisted,” “augmented,” or something less fashionable, the point remains the same: the right blend of tools and expertise can turn one of the industry’s thorniest problems into an area of real progress.
References
Javkhedkar, A. & Shah, S., LLMs in Clinical Trials: Overcoming Challenges (PhUSE US Conference, 2025).
Young, R. J. et al., Benchmarking Multiple LLMs for Automated Clinical Trial Data Extraction, Algorithms 18(5): 296, 2025.
Medidata, AI in Clinical Study Builds: Redefining EDC Efficiency (Blog post, Aug 15, 2025).
Vertesia, Semantic DocPrep: Giving Your LLM True Understanding (Blog post, Jun 10, 2025).
Morphomix Mandate, “Stitching Point-Solutions into a Coherent Whole”, Substack (2025).
Morphomix Mandate, “The Morphomix Mandate: Evolution of AI Strategy”, Substack (2025).